java.nio.ByteBuffer
java.nio.ByteBuffer
Java NIO Buffers用于和NIO Channel交互。 我们从Channel中读取数据到buffers里,从Buffer把数据写入到Channels。Buffer本质上就是一块内存区,可以用来写入数据,并在稍后读取出来。这块内存被NIO Buffer包裹起来,对外提供一系列的读写方便开发的接口。java中java.nio.Buffer的常见实现类如下,不过我们这里只说一下ByteBuffer这个实现。
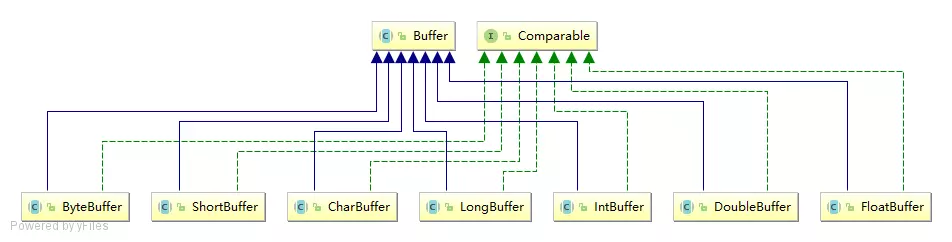
java.nio.Buffer的常见实现类Buffer的重要属性
Buffer缓冲区实质上就是一块内存,用于写入数据,也供后续再次读取数据,为了便于理解,你可以把它理解为一个字节数组。它有有四个重要属性:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
}
capacity- 这个属性表示这个Buffer最多能放多少数据,在创建buffer的时候指定。int类型。
position下一个要读写的元素位置(从0开始),当使用buffer的相对位置进行读/写操作时,读/写会从这个下标进行,并在操作完成后,buffer会更新下标的值。- 写模式:当写入数据到Buffer的时候需要从一个确定的位置开始,默认初始化时这个位置position为0,一旦写入了数据比如一个字节,整形数据,那么position的值就会指向数据之后的一个单元,position最大可以到
capacity-1. - 读模式:当从Buffer读取数据时,也需要从一个确定的位置开始。buffer从写入模式变为读取模式时,position会归0,每次读取后,position向后移动。
- 写模式:当写入数据到Buffer的时候需要从一个确定的位置开始,默认初始化时这个位置position为0,一旦写入了数据比如一个字节,整形数据,那么position的值就会指向数据之后的一个单元,position最大可以到
limit在Buffer上进行的读写操作都不能越过这个limit。- 写模式:limit的含义是我们所能写入的最大数据量,它等同于buffer的容量capacity
- 读模式:limit则代表我们所能读取的最大数据量,他的值等同于写模式下position的位置。换句话说,您可以读取与写入数量相同的字节数。
mark- 一个临时存放的位置下标,用户选定的position的前一个位置或-1。
- 调用
mark()会将mark设为当前的position的值,以后调用reset()会将position属性设 置为mark的值。mark的值总是小于等于position的值,如果将position的值设的比mark小,当前的mark值会被抛弃掉。
- 调用
- 一个临时存放的位置下标,用户选定的position的前一个位置或-1。
注:
- position和limit之间的距离指示了可读/存的字节数。
- boolean hasRemaining():当缓冲区至少还有一个元素时,返回true。
- int remaining():position和limit之间字节个数。
这些属性总是满足以下条件:
0 <= mark <= position <= limit <= capacity
通过上面的描述可以看出,其中position和limit的具体含义取决于当前buffer的模式(读模式还是写模式)。capacity在两种模式下都表示容量。
Buffer的常见API
- ByteBuffer allocate(int capacity)
- 从堆空间中分配一个容量大小为capacity的byte数组作为缓冲区的byte数据存储器,实现类是
HeapByteBuffer。
- 从堆空间中分配一个容量大小为capacity的byte数组作为缓冲区的byte数据存储器,实现类是
- ByteBuffer allocateDirect(int capacity)
- 类似于allocate方法,不过使用的是对外内存,实现类是
DirectByteBuffer。
- 类似于allocate方法,不过使用的是对外内存,实现类是
- ByteBuffer wrap(byte[] array)
- 把byte数组包装为ByteBuffer,bytes数组或buff缓冲区任何一方中数据的改动都会影响另一方。其实ByteBuffer底层本来就有一个bytes数组负责来保存buffer缓冲区中的数据,通过allocate方法系统会帮你构造一个byte数组,实现类是
HeapByteBuffer。
- 把byte数组包装为ByteBuffer,bytes数组或buff缓冲区任何一方中数据的改动都会影响另一方。其实ByteBuffer底层本来就有一个bytes数组负责来保存buffer缓冲区中的数据,通过allocate方法系统会帮你构造一个byte数组,实现类是
- ByteBuffer wrap(byte[] array, int offset, int length)
- 在上一个方法的基础上可以指定偏移量和长度,buffer的capacity就是array.length,这个offset也就是包装后byteBuffer的position,limit=length+position(offset),mark=-1实现类是
HeapByteBuffer。
- 在上一个方法的基础上可以指定偏移量和长度,buffer的capacity就是array.length,这个offset也就是包装后byteBuffer的position,limit=length+position(offset),mark=-1实现类是
- abstract Object array()
- 返回支持此缓冲区的数组 (可选操作)
- abstract int arrayOffset()
- 返回此缓冲区中的第一个元素在缓冲区的底层实现数组中的偏移量(可选操作)。调用此方法之前要调用
hasarray方法,以确保此缓冲区具有可访问的底层实现数组。
- 返回此缓冲区中的第一个元素在缓冲区的底层实现数组中的偏移量(可选操作)。调用此方法之前要调用
- abstract boolean hasArray()
- 告诉这个缓冲区是否由可访问的数组支持
- int capacity()
- 返回此缓冲区的容量
- Buffer clear()
- 清除此缓存区。将position = 0;limit = capacity;mark = -1;把position设为0,一般在把数据写入Buffer前调用。
- Buffer flip()
- flip()方法可以吧Buffer从写模式切换到读模式。调用flip方法会把position归零,并设置limit为之前的position的值。也就是说,现在position代表的是读取位置,limit标示的是已写入的数据位置。一般在从Buffer读出数据前调用。
- abstract boolean isDirect()
- 判断个缓冲区是否为direct, 也就是是否是对外内存
- abstract boolean isReadOnly()
- 判断告知这个缓冲区是否是只读的
- int limit()
- 返回此缓冲区的limit的属性值
- Buffer position(int newPosition)
- 设置这个缓冲区的位置
- boolean hasRemaining()
- return position < limit,返回是否还有未读内容
- int remaining()
- return limit - position; 返回limit和position之间相对位置差
- Buffer rewind()
- 把position设为0,mark设为-1,不改变limit的值,一般在把数据重写入Buffer前调用
- Buffer mark()
- 设置mark的值,mark=position,做个标记
- Buffer reset()
- 还原标记,position=mark。
- ByteBuffer compact()
- 该方法的作用是将 position 与 limit之间的数据复制到buffer的开始位置,与limit 之间没有数据的话发,就不会进行复制。一个例子如下:
例如:ByteBuffer.allowcate(10);
内容:[0 ,1 ,2 ,3 4, 5, 6, 7, 8, 9]
## compact前
[0 ,1 ,2 , 3, 4, 5, 6, 7, 8, 9]
pos=4
lim=10
cap=10
## compact后
[4, 5, 6, 7, 8, 9, 6, 7, 8, 9]
pos=6
lim=10
cap=10
- ByteBuffer slice();
- 创建一个分片缓冲区。分片缓冲区与主缓冲区共享数据。 分配的起始位置是主缓冲区的position位置,容量为limit-position。 分片缓冲区无法看到主缓冲区positoin之前的元素。
创建buffer的注意点
创建ByteBuffer可以使用allocate或者wrap,就像下面这样:
- ByteBuffer allocate(int capacity)
- ByteBuffer allocateDirect(int capacity)
- ByteBuffer wrap(int capacity)
- ByteBuffer wrap(byte[] array,int offset,int length)
需要注意的是:创建的缓冲区都是定长的,大小无法改变。若发现刚创建的缓冲区容量太小,只能重新创建一个合适的。
关于ByteBuffer wrap(byte[] array,int offset,int length)这个方法,这里再强调一下,这样创建的ByteBuffer的capacity和array的大小是一样的,buffer的position是offset, buffer的limit是offset+length,position之前和limit之后的数据依然可以访问到。例子如下:
public class Demo {
public static void main(String args[]){
byte arr[]=new byte[100];
ByteBuffer buffer=ByteBuffer.wrap(arr,3,25);
System.out.println("Capacity is: "+buffer.capacity());
System.out.println("Position is: "+buffer.position());
System.out.println("limit is: "+buffer.limit());
}
}
//结果:
Capacity is: 100
Position is: 3
limit is: 28
allocate和wrap的区别
wrap只是简单地创建一个具有指向被包装数组的引用的缓冲区,该数组成为后援数组。对后援数组中的数据做的任何修改都将改变缓冲区中的数据,反之亦然。
public static void main(String args[]){
byte arr[]=new byte[100];
//将arr数组全部置为1
Arrays.fill(arr, (byte)1);
ByteBuffer buffer=ByteBuffer.wrap(arr,3,25);
//对后援数组中的数据做的任何修改都将改变缓冲区中的数据
arr[0]=(byte)2;
buffer.position(0);
System.out.println(buffer.get());
//在缓冲区上调用array()方法即可获得后援数组的引用。
System.out.println(Arrays.toString(buffer.array()));
}
//运行结果:
2
[2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ....]//总共100个元素
allocate则是创建了自己的后援数组,在缓冲区上调用array()方法也可获得后援数组的引用。通过调用arrayOffset()方法,可以获取缓冲区中第一个元素在后援数组的偏移量。但是使用wrap创建的ByteBuffer,调用arrayOffset永远是0。
public static void main(String args[]){
ByteBuffer buffer=ByteBuffer.allocate(100);
//对后援素组的修改也可以反映到buffer上
byte arr[]=buffer.array();
arr[1]=(byte)'a';
buffer.getInt();
System.out.println(Arrays.toString(buffer.array()));
System.out.println(buffer.arrayOffset());
}
//运行结果:
[0, 97, 0, 0, 0, 0, 0, 0,...]//总共100个元素
0
通过ByteBuffer allocateDirect(int capacity)创建的叫直接缓冲区,使用的堆外内存。可以通过isDirect()方法查看一个缓冲区是否是直接缓冲区。由于直接缓冲区是没有后援数组的,所以在其上面调用array()或arrayOffset()都会抛出UnsupportedOperationException异常。注意有些平台或JVM可能不支持这个创建直接缓冲区。
图解
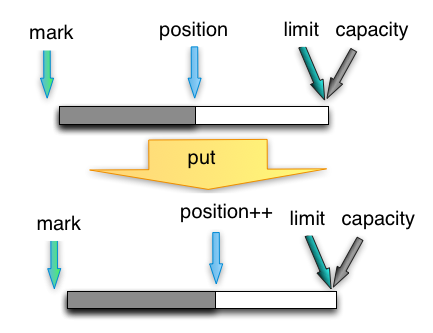
put
写模式下,往buffer里写一个字节,并把postion移动一位。写模式下,一般limit与capacity相等。
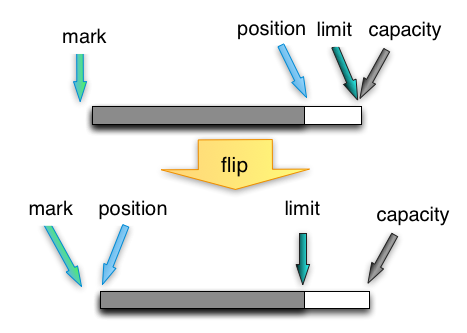
flip
写完数据,需要开始读的时候,将postion复位到0,并将limit设为当前postion。
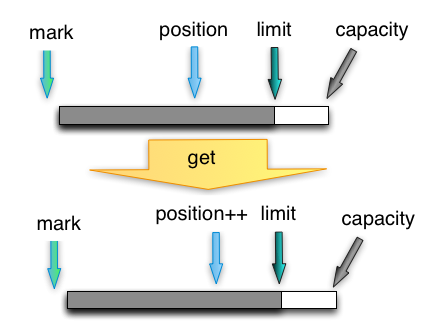
get
从buffer里读一个字节,并把postion移动一位。上限是limit,即写入数据的最后位置。
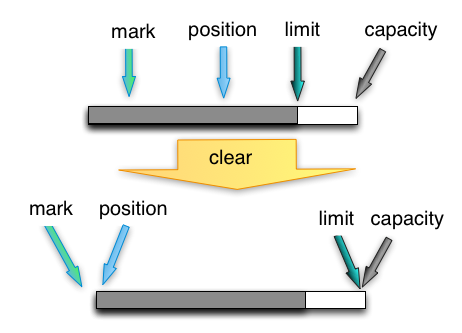
clear
将position置为0,并不清除buffer内容。
example
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class Demo {
private static final int SIZE = 1024;
public static void main(String[] args) throws Exception {
// 获取通道,该通道允许写操作
FileChannel fc = new FileOutputStream("data.txt").getChannel();
// 将字节数组包装到缓冲区中
fc.write(ByteBuffer.wrap("Some text".getBytes()));
// 关闭通道
fc.close();
// 随机读写文件流创建的管道
fc = new RandomAccessFile("data.txt", "rw").getChannel();
// fc.position()计算从文件的开始到当前位置之间的字节数
System.out.println("此通道的文件位置:" + fc.position());
// 设置此通道的文件位置,fc.size()此通道的文件的当前大小,该条语句执行后,通道位置处于文件的末尾
fc.position(fc.size());
// 在文件末尾写入字节
fc.write(ByteBuffer.wrap("Some more".getBytes()));
fc.close();
// 用通道读取文件
fc = new FileInputStream("data.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(SIZE);
// 将文件内容读到指定的缓冲区中
fc.read(buffer);
//此行语句一定要有, 如果没有,就是从文件最后开始读取的,当然读出来的都是byte=0时候的字符。通过buffer.flip();这个语句,就能把buffer的当前位置更改为buffer缓冲区的第一个位置
buffer.flip();
while (buffer.hasRemaining()) {
System.out.print((char)buffer.get());
}
fc.close();
}
}
版权申明
本站点所有内容,版权均归https://wenchao.ren所有,除非明确授权,否则禁止一切形式的转载协议
打赏


