Reactor核心特性
Reactor核心特性
Reactor 项目的主要工件是 reactor-core ,这是一个专注于 Reactive Streams 规范并针对 Java 8 的反应式库。
Reactor 引入了可组合的反应类型,它实现了 Publisher ,但也提供了丰富的运算符词汇: Flux 和 Mono 。 Flux 对象表示 0..N 个项目的反应序列,而 Mono 对象表示单值或空 (0..1) 结果。
这种区别将一些语义信息带入类型中,指示异步处理的粗略基数。例如,HTTP 请求仅产生一个响应,因此执行 count 操作没有多大意义。因此,将此类 HTTP 调用的结果表示为 Mono<HttpResponse> 比将其表示为 Flux<HttpResponse> 更有意义,因为它仅提供与零个或一个项目的上下文相关的运算符物品。更改处理的最大基数的运算符也会切换到相关类型。例如, count 运算符存在于 Flux 中,但它返回 Mono<Long> 。
Flux ,0-N 项的异步序列
下图显示了 Flux 如何转换项目:
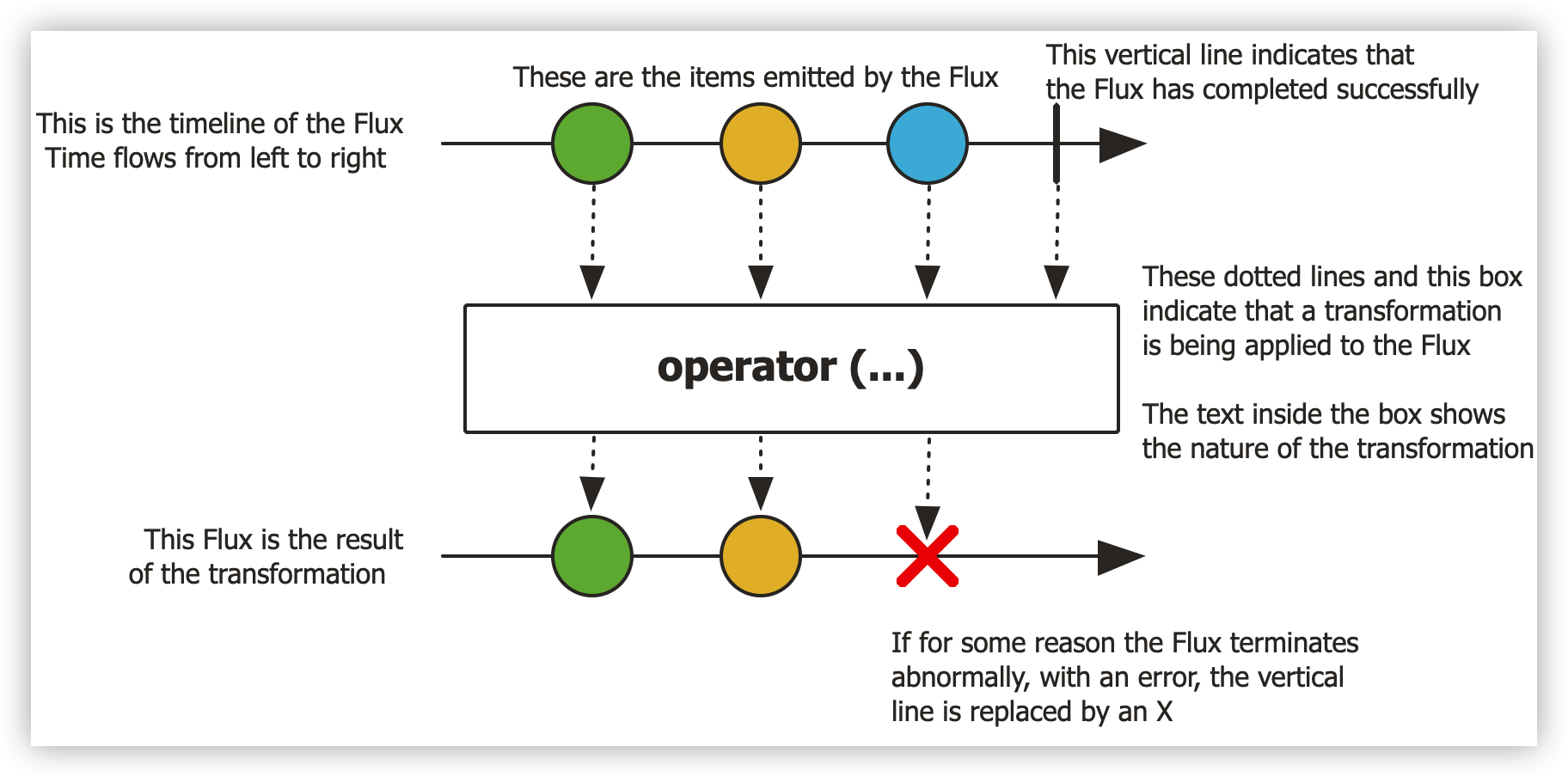
Flux<T> 是标准 Publisher<T> ,表示 0 到 N 个发出项目的异步序列,可以选择由完成信号或错误终止。与反应流规范中一样,这三种类型的信号转换为对下游订阅者的 onNext 、 onComplete 和 onError 方法的调用。
有了这么多可能的信号范围,Flux是通用的响应式类型。请注意,所有事件,即使是终止事件,都是可选的:没有onNext事件但有一个onComplete事件表示一个空的有限序列,但是如果去掉onComplete,你就得到了一个无限的空序列(除了测试取消方面,不是特别有用)。同样,无限序列不一定是空的。例如,Flux.interval(Duration)会产生一个Flux<Long>,它是无限的,并从时钟发出定期的tick。
Mono ,异步 0-1 结果
下图显示了 Mono 如何转换项目:
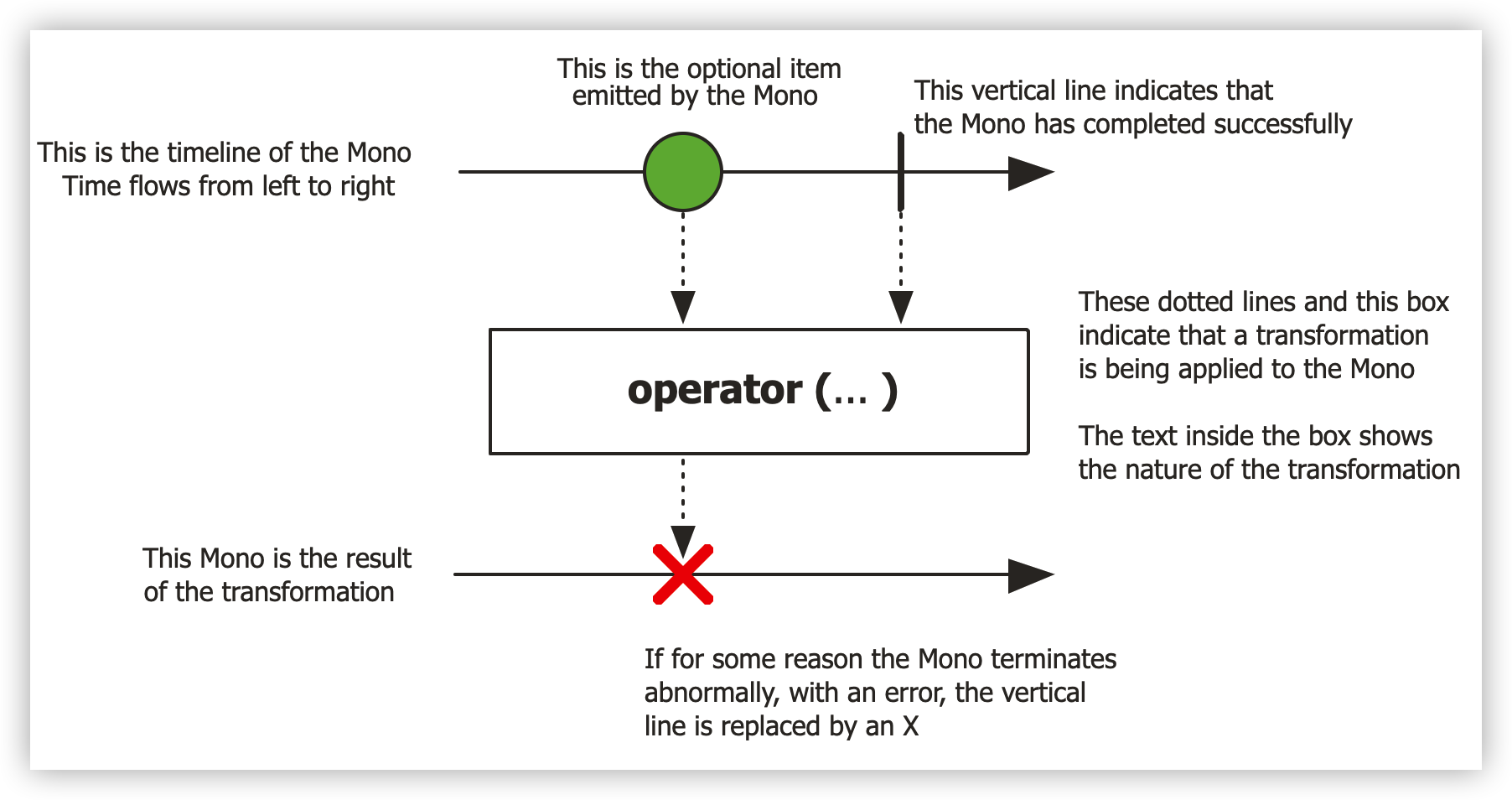
Mono<T> 是一种专门的 Publisher<T> ,它通过 onNext 信号最多发出一项,然后以 onComplete 信号终止(成功的 Mono ,有或没有值),或仅发出单个 onError 信号(失败 Mono )。
大多数 Mono 实现在调用 onNext 后应立即在其 Subscriber 上调用 onComplete 。 Mono.never() 是一个异常值:它不发出任何信号,这在技术上并没有被禁止,尽管在测试之外并不是很有用。另一方面,明确禁止 onNext 和 onError 的组合。
Mono 仅提供可用于 Flux 的运算符子集,以及一些运算符(特别是那些将 Mono 与另一个 Publisher 。例如, Mono#concatWith(Publisher) 返回 Flux 而 Mono#then(Mono) 返回另一个 Mono 。
请注意,您可以使用 Mono 来表示仅具有完成概念的无值异步流程(类似于 Runnable )。要创建一个,您可以使用空的 Mono<Void> 。
创建 Flux 或 Mono 并订阅它的简单方法
开始使用 Flux 和 Mono 的最简单方法是使用在各自类中找到的众多工厂方法之一。
例如,要创建 String 序列,您可以枚举它们或将它们放入集合中并从中创建 Flux,如下所示:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);
工厂方法的其他示例包括:
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);
在订阅方面, Flux 和 Mono 使用 Java 8 lambda。您可以选择多种 .subscribe() 变体,这些变体采用 lambda 来实现不同的回调组合,如以下方法签名所示:
`Flux` 基于 Lambda 的订阅变体
subscribe();
subscribe(Consumer<? super T> consumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
这些变体返回对订阅的引用,您可以在不需要更多数据时使用该引用取消订阅。取消后,源应停止生成值并清理其创建的所有资源。这种取消和清理行为在 Reactor 中由通用 Disposable 接口表示。
subscribe 方法示例
本节包含 subscribe 方法的五个签名中每个签名的最小示例。以下代码显示了不带参数的基本方法的示例:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe();
前面的代码不会产生可见的输出,但它确实有效。 Flux 产生三个值。如果我们提供 lambda,我们就可以使值可见。 subscribe 方法的下一个示例显示了显示值的一种方法:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe(i -> System.out.println(i));
为了演示下一个签名,我们故意引入一个错误,如下例所示:
Flux<Integer> ints = Flux.range(1, 4)
.map(i -> {
if (i <= 3) return i;
throw new RuntimeException("Got to 4");
});
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error: " + error));
上述代码输出如下:
1
2
3
Error: java.lang.RuntimeException: Got to 4
subscribe 方法的下一个签名包括错误处理程序和完成事件处理程序,如以下示例所示:
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> System.out.println("Done"));
错误信号和完成信号都是终止事件并且是互斥的(你永远不会同时得到两者)。为了使完成消费者工作,我们必须注意不要触发错误。
完成回调没有输入,由一对空括号表示:它与 Runnable 接口中的 run 方法匹配。前面的代码产生以下输出:
1
2
3
4
Done
使用 Disposable 取消 subscribe()
所有这些基于 lambda 的 subscribe() 变体都有一个 Disposable 返回类型。在本例中, Disposable 接口表示可以通过调用其 dispose() 方法来取消订阅。
对于 Flux 或 Mono ,取消是源应停止生成元素的信号。但是,不能保证立即执行:某些源可能会非常快地生成元素,甚至在收到取消指令之前它们就可以完成。
一些与“Disposable”相关的实用工具可以在“Disposables”类中找到。其中,“Disposables.swap()”创建了一个“Disposable”包装器,使您可以原子地取消和替换具体的“Disposable”。例如,在UI场景中,当用户单击按钮时,您想要取消一个请求并用新的请求替换它,这时就可以使用它。释放包装器本身会关闭它。这样做会处理当前的具体值和所有未来尝试的替换。
另一个有趣的实用程序是 Disposables.composite(…) 。此组合允许您收集多个 Disposable — 例如,与服务调用关联的多个正在进行的请求 — 并稍后立即处理所有这些请求。一旦组合的 dispose() 方法被调用,任何添加另一个 Disposable 的尝试都会立即释放它。
Lambda 的替代方案: BaseSubscriber
还有一种更通用的 subscribe 方法,它采用成熟的 Subscriber ,而不是从 lambda 中组合一个。为了帮助编写这样的 Subscriber ,我们提供了一个名为 BaseSubscriber 的可扩展类。
BaseSubscriber (或其子类)的实例是一次性的,这意味着如果 BaseSubscriber 订阅了第二个 Publisher ,则它会取消对第一个 Publisher 的订阅 Publisher 。这是因为使用一个实例两次会违反反应流规则,即 Subscriber 的 onNext 方法不得并行调用。因此,只有直接在 Publisher#subscribe(Subscriber) 调用中声明匿名实现才可以。
package io.projectreactor.samples;
import org.reactivestreams.Subscription;
import reactor.core.publisher.BaseSubscriber;
public class SampleSubscriber<T> extends BaseSubscriber<T> {
public void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed");
request(1);
}
public void hookOnNext(T value) {
System.out.println(value);
request(1);
}
}
SampleSubscriber<Integer> ss = new SampleSubscriber<Integer>();
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(ss);
//输出如下:
Subscribed
1
2
3
4
SampleSubscriber 类扩展了 BaseSubscriber ,它是 Reactor 中用户定义的 Subscribers 推荐的抽象类。该类提供了可以重写的挂钩来调整订阅者的行为。默认情况下,它会触发无界请求,其行为与 subscribe() 完全相同。但是,当您需要自定义请求量时,扩展 BaseSubscriber 会更有用。
对于自定义请求量,最低限度是实现 hookOnSubscribe(Subscription subscription) 和 hookOnNext(T value) ,就像我们所做的那样。在我们的例子中, hookOnSubscribe 方法将一条语句打印到标准输出并发出第一个请求。然后 hookOnNext 方法打印一条语句并执行其他请求,一次一个请求。
BaseSubscriber 还提供了 requestUnbounded() 方法来切换到无界模式(相当于 request(Long.MAX_VALUE) ),以及 cancel() 方法。
它还具有额外的钩子: hookOnComplete 、 hookOnError 、 hookOnCancel 和 hookFinally (当序列终止时总是调用它,带有作为 SignalType 参数传入的终止类型)
您几乎肯定想要实现 hookOnError 、 hookOnCancel 和 hookOnComplete 方法。您可能还想实现 hookFinally 方法。 SampleSubscriber 是执行有界请求的 Subscriber 的绝对最小实现。
关于背压和重塑请求的方法
在 Reactor 中实现背压时,消费者压力传播回源的方式是向上游算子发送 request 。当前请求的总和有时被称为当前“需求”或“待处理请求”。需求上限为 Long.MAX_VALUE ,代表无限制的请求(意味着“尽可能快地生产”——基本上禁用背压)。
第一个请求来自订阅时的最终订阅者,但最直接的订阅方式都会立即触发 Long.MAX_VALUE 的无限请求:
- subscribe() 及其大多数基于 lambda 的变体(具有
Consumer<Subscription>的变体除外) - block() 、 blockFirst() 和 blockLast()
- 迭代
toIterable() 或toStream()
自定义原始请求的最简单方法是将 subscribe 与 BaseSubscriber 结合使用,并覆盖 hookOnSubscribe 方法,如以下示例所示:
Flux.range(1, 10)
.doOnRequest(r -> System.out.println("request of " + r))
.subscribe(new BaseSubscriber<Integer>() {
@Override
public void hookOnSubscribe(Subscription subscription) {
request(1);
}
@Override
public void hookOnNext(Integer integer) {
System.out.println("Cancelling after having received " + integer);
cancel();
}
});
//输出:
request of 1
Cancelling after having received 1
在操作请求时,您必须小心地产生足够的需求以使序列前进,否则您的 Flux 可能会“卡住”。这就是为什么 BaseSubscriber 默认为 hookOnSubscribe 中的无界请求。当覆盖此钩子时,您通常应该至少调用一次 request 。
Operators that Change the Demand from Downstream
需要记住的一件事是,上游链中的每个运算符都可以重塑订阅级别表达的需求。一个教科书案例是 buffer(N) 运算符:如果它接收到 request(2) ,则它被解释为对两个完整缓冲区的需求。因此,由于缓冲区需要 N 元素才能被视为已满,因此 buffer 运算符将请求重塑为 2 x N 。
您可能还注意到,某些运算符具有采用名为 prefetch 的 int 输入参数的变体。这是修改下游请求的另一类运算符。这些通常是处理内部序列的运算符,从每个传入元素派生出 Publisher (如 flatMap )。
Prefetch是一种调整对这些内部序列发出的初始请求的方法。如果未指定,大多数这些运算符都以 32 需求开始。
这些操作符通常还会实现补充优化(replenishing optimization):一旦操作符看到 75% 的预取请求已得到满足,它就会从上游重新请求 75%。这是一种启发式优化,以便这些操作员能够主动预测即将到来的请求。
最后,几个运算符可让您直接调整请求: limitRate 和 limitRequest 。
limitRate(N) 拆分下游请求,以便它们以较小的批次向上游传播。例如,向 limitRate(10) 发出的 100 请求最多会导致 10 的 10 个请求传播到上游。请注意,在这种形式中, limitRate 实际上实现了前面讨论的补充优化。
操作员有一种变体,它还可以让您调整补充数量(在变体中称为lowTide):limitRate(highTide,lowTide)。选择lowTide为0会导致highTide请求的严格批处理,而不是通过replenishing optimization进一步重新处理的批处理。
The operator has a variant that also lets you tune the replenishing amount (referred to as the
lowTide in the variant):limitRate(highTide, lowTide). Choosing alowTide of0 results in strict batches ofhighTide requests, instead of batches further reworked by the replenishing strategy.
另一方面,limitRequest(N)将下游请求限制为最大的总需求量。它将请求相加,直到达到N。如果单个请求不会使总需求量超过N,那么该特定请求就会完全向上游传播。在源发出该数量后,limitRequest将考虑序列已完成,向下游发出onComplete信号并取消源。
以编程方式创建序列
在本节中,我们将介绍通过以编程方式定义其关联事件( onNext 、 onError 和 onComplete )。所有这些方法都有一个共同的事实:它们公开一个 API 来触发我们称为接收器的事件。实际上有一些sink变体,我们很快就会介绍。
Synchronous generate
以编程方式创建 Flux 的最简单形式是通过 generate 方法,该方法采用生成器函数。
这适用于同步和一对一的发射,这意味着sink是一个 SynchronousSink 并且它的 next() 方法每次回调调用最多只能调用一次。然后,您可以另外调用 error(Throwable) 或 complete() ,但这是可选的。
最有用的变体可能还可以让您保留一种状态,您可以在接收器使用中参考该状态来决定下一步要发出什么。然后生成器函数变成 BiFunction<S, SynchronousSink<T>, S> ,其中 <S> 是状态对象的类型。您必须为初始状态提供 Supplier<S> ,并且您的生成器函数现在在每一轮返回一个新状态。
基于状态的 generate 示例:
Flux<String> flux = Flux.generate(
() -> 0, //我们提供初始状态值 0,这行是一个`Supplier`
(state, sink) -> {
sink.next("3 x " + state + " = " + 3*state); //我们使用状态来选择要发出的内容。
if (state == 10) sink.complete(); //我们还用它来选择何时停止。
return state + 1; //我们返回一个在下一次调用中使用的新状态(除非序列在本次调用中终止)。
});
//程序输出如下:
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
3 x 6 = 18
3 x 7 = 21
3 x 8 = 24
3 x 9 = 27
3 x 10 = 30
您还可以使用可变的<S> 。例如,可以使用单个 AtomicLong 作为状态来重写上面的示例,并在每一轮中对其进行变异:
Flux<String> flux = Flux.generate(
AtomicLong::new, //这次,我们生成一个可变对象作为状态。
(state, sink) -> {
long i = state.getAndIncrement(); //我们在这里改变状态。
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state; //我们返回与新状态相同的实例。
});
如果您的状态对象需要清理一些资源,请使用 generate(Supplier<S>, BiFunction, Consumer<S>) 变体来清理最后一个状态实例。
以下示例使用包含 Consumer 的 generate 方法:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
}, (state) -> System.out.println("state: " + state)); //我们将最后一个状态值 (11) 视为此 Consumer lambda 的输出。
如果状态包含数据库连接或需要在流程结束时处理的其他资源, Consumer lambda 可以关闭连接或以其他方式处理应在结束时完成的任何任务的过程。
Asynchronous and Multi-threaded: create
create 是 Flux 的编程创建的更高级形式,适用于每轮多次发射,甚至来自多个线程。
它公开了 FluxSink 及其 next 、 error 和 complete 方法。与 generate 相反,它没有基于状态的变体。另一方面,它可以在回调中触发多线程事件。
create 对于桥接现有 API 与反应式世界非常有用 - 例如基于侦听器的异步 API。
create 不会并行化您的代码,也不会使其异步,即使它可以与异步 API 一起使用。如果您在 create lambda 中进行阻塞,则会面临死锁和类似副作用的风险。即使使用 subscribeOn ,也需要注意的是,长阻塞 create lambda(例如调用 sink.next(t) 的无限循环)可能会锁定管道:请求永远不会被执行,因为循环使它们应该运行的同一线程处于饥饿状态。使用 subscribeOn(Scheduler, false) 变体: requestOnSeparateThread = false 将为 create 使用 Scheduler 线程,并且仍然通过执行 request
假设您使用基于侦听器的 API。它按块处理数据并有两个事件:(1) 数据块已准备好,(2) 处理完成(终止事件),如 MyEventListener 界面所示:
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
您可以使用 create 将其桥接到 Flux<T> :
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register( //每当 myEventProcessor 执行时,所有这些都是异步完成的。
new MyEventListener<String>() { //桥接到 MyEventListener API
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); //块中的每个元素都成为 Flux 中的元素。
}
}
public void processComplete() {
sink.complete(); //processComplete 事件被转换为 onComplete 。
}
});
});
此外,由于 create 可以桥接异步 API 并管理反压,因此您可以通过指示 OverflowStrategy 来细化反压行为方式:
- IGNORE 完全忽略下游背压请求。当下游队列已满时,这可能会产生 IllegalStateException 。
- ERROR 当下游无法跟上时发出 IllegalStateException 信号。
- DROP 如果下游未准备好接收传入信号,则丢弃该信号。
- LATEST 让下游只获取来自上游的最新信号。
- BUFFER (默认)在下游无法跟上时缓冲所有信号。 (这会进行无限制的缓冲,并可能导致 OutOfMemoryError )。
Mono 还有一个 create 生成器。 Mono 的 MonoSink 不允许多次发射。它将丢弃第一个信号之后的所有信号。
Asynchronous but single-threaded: push
push 是 generate 和 create 之间的中间立场,适合处理来自单个生产者的事件。它与 create 类似,因为它也可以是异步的,并且可以使用 create 支持的任何溢出策略来管理背压。然而,一次只有一个生产线程可以调用 next 、 complete 或 error 。
Flux<String> bridge = Flux.push(sink -> {
myEventProcessor.register(
new SingleThreadEventListener<String>() { //桥接到 SingleThreadEventListener API。
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); //使用 next 从单个侦听器线程将事件推送到接收器。
}
}
public void processComplete() {
sink.complete(); //从同一侦听器线程生成的 complete 事件。
}
public void processError(Throwable e) {
sink.error(e); //error 事件也从同一侦听器线程生成。
}
});
});
A hybrid push/pull model
大多数 Reactor 运算符(例如 create )遵循混合推/拉模型。我们的意思是,尽管大部分处理是异步的(建议采用推送方法),但其中有一个小的拉取组件:request。
消费者从源pull数据,这意味着在第一次请求之前它不会发出任何东西。每当源中有数据可用时,源就向消费者push数据,但在其所请求的量范围内。
请注意, push() 和 create() 都允许设置 onRequest 消费者,以便管理请求量并确保仅在以下情况下才通过接收器推送数据:有待处理的请求。
Flux<String> bridge = Flux.create(sink -> {
myMessageProcessor.register(
new MyMessageListener<String>() {
public void onMessage(List<String> messages) {
for(String s : messages) {
sink.next(s); //稍后异步到达的剩余消息也会被传递。
}
}
});
sink.onRequest(n -> {
List<String> messages = myMessageProcessor.getHistory(n); //发出请求时轮询消息。
for(String s : messages) {
sink.next(s); //如果消息立即可用,则将它们推送到接收器。
}
});
});
Cleaning up after push() or create()
两个回调 onDispose 和 onCancel 在取消或终止时执行任何清理。 onDispose 可用于在 Flux 完成、出错或取消时执行清理。 onCancel 可用于在使用 onDispose 进行清理之前执行任何特定于取消的操作。
Flux<String> bridge = Flux.create(sink -> {
sink.onRequest(n -> channel.poll(n))
.onCancel(() -> channel.cancel()) //onCancel 首先被调用,仅用于取消信号
.onDispose(() -> channel.close()) //onDispose 被调用用于完成、错误或取消信号。
});
Handle
handle 方法有点不同:它是一个实例方法,这意味着它链接在现有源上(与常见运算符一样)。它出现在 Mono 和 Flux 中。
它接近于 generate ,因为它使用 SynchronousSink 并且只允许一对一的发射。但是, handle 可用于从每个源元素生成任意值,可能会跳过某些元素。这样,它就可以作为 map 和 filter 的组合。句柄签名如下:Flux<R> handle(BiConsumer<T, SynchronousSink<R>>);
让我们考虑一个例子。反应式流规范不允许序列中存在 null 值。如果您想要执行 map 但想要使用预先存在的方法作为映射函数,并且该方法有时返回 null,该怎么办?
public String alphabet(int letterNumber) {
if (letterNumber < 1 || letterNumber > 26) {
return null;
}
int letterIndexAscii = 'A' + letterNumber - 1;
return "" + (char) letterIndexAscii;
}
然后我们可以使用 handle 删除任何空值:
Flux<String> alphabet = Flux.just(-1, 30, 13, 9, 20)
.handle((i, sink) -> {
String letter = alphabet(i);
if (letter != null)
sink.next(letter);
});
alphabet.subscribe(System.out::println);
线程和调度程序
Reactor 与 RxJava 一样,可以被认为是与并发无关的。也就是说,它不强制执行并发模型。相反,它让你(开发人员)来指挥。但是,这并不妨碍该库帮助您处理并发性。
获取 Flux 或 Mono 并不一定意味着它在专用的 Thread 中运行。相反,大多数运算符继续在前一个运算符执行的 Thread 中工作。除非指定,否则最顶层的运算符(源)本身在进行 subscribe() 调用的 Thread 上运行。以下示例在新线程中运行 Mono :
public static void main(String[] args) throws InterruptedException {
final Mono<String> mono = Mono.just("hello "); //Mono<String> 在线程 main 中组装。
Thread t = new Thread(() -> mono
.map(msg -> msg + "thread ")
.subscribe(v -> //但是,它是在线程 Thread-0 中订阅的。
System.out.println(v + Thread.currentThread().getName())
//因此, map 和 onNext 回调实际上都在 Thread-0 中运行
)
)
t.start();
t.join();
}
//output
hello thread Thread-0
在 Reactor 中,执行模型和执行发生的位置由所使用的 Scheduler 决定。 Scheduler 具有与 ExecutorService 类似的调度职责,但是拥有专用的抽象可以让它做更多的事情,特别是充当时钟并支持更广泛的实现(测试的虚拟时间,蹦床(trampolining)或立即调度等)。
Schedulers 类具有静态方法,可以访问以下执行上下文:
无执行上下文(
Schedulers.immediate() ):在处理时,提交的Runnable 将被直接执行,有效地将它们运行在当前的Thread 上(可以看作是“空对象”或无操作Scheduler )。单个可重用线程 (
Schedulers.single() )。请注意,此方法为所有调用者重用同一线程,直到调度程序被释放。如果您想要每个调用专用线程,请为每个调用使用Schedulers.newSingle() 。无界弹性线程池 (
Schedulers.elastic() )。随着Schedulers.boundedElastic() 的引入,这个不再是首选,因为它有隐藏背压问题并导致太多线程的趋势(见下文)。有界弹性线程池 (
Schedulers.boundedElastic() )。与它的前身elastic() 一样,它根据需要创建新的工作池并重用空闲的工作池。闲置时间过长(默认为 60 秒)的工作池也会被丢弃。与它的前身elastic() 不同,它对可以创建的支持线程数量有上限(默认为 CPU 核心数量 x 10)。达到上限后提交的最多 100 000 个任务将被排队,并在线程可用时重新调度(当延迟调度时,延迟在线程可用时开始)。- 这是 I/O 阻塞工作的更好选择。
Schedulers.boundedElastic() 是一种为阻塞进程提供自己的线程的便捷方法,这样它就不会占用其他资源。
- 这是 I/O 阻塞工作的更好选择。
为并行工作而调整的固定工作人员池 ( Schedulers.parallel() )。它会创建与 CPU 核心数量一样多的工作线程。
此外,您可以使用 Schedulers.fromExecutorService(ExecutorService) 从任何预先存在的 ExecutorService 中创建 Scheduler 。 (您也可以从 Executor 创建一个,但不鼓励这样做。)
您还可以使用 newXXX 方法创建各种调度程序类型的新实例。例如, Schedulers.newParallel(yourScheduleName) 创建一个名为 yourScheduleName 的新并行调度程序。
- 虽然
boundedElastic 是为了帮助处理无法避免的遗留阻塞代码,但single 和parallel 则不然。因此,使用 Reactor 阻塞 API(block() 、blockFirst() 、blockLast() (以及迭代toIterable() 或toStream() )在默认的单一和并行调度程序中)会导致抛出IllegalStateException 。 - 自定义 Schedulers 还可以通过创建实现 NonBlocking 标记接口的 Thread 实例来标记为“仅非阻塞”。
某些运算符默认使用 Schedulers 中的特定调度程序(并且通常允许您选择提供不同的调度程序)。例如,调用 Flux.interval(Duration.ofMillis(300)) 工厂方法会生成每 300 毫秒计时一次的 Flux<Long> 。默认情况下,这是由 Schedulers.parallel() 启用的。以下行将 Scheduler 更改为类似于 Schedulers.single() 的新实例:Flux.interval(Duration.ofMillis(300), Schedulers.newSingle("test"))。
Reactor 提供了两种在反应链中切换执行上下文(或 Scheduler )的方法: publishOn 和 subscribeOn 。两者都采用 Scheduler 并让您将执行上下文切换到该调度程序。但是 publishOn 在链中的位置很重要,而 subscribeOn 的位置则无关紧要。要理解这种差异,您首先必须记住,在您订阅之前什么都不会发生。
在 Reactor 中,当您链接运算符时,您可以根据需要将任意多个 Flux 和 Mono 实现相互包装起来。一旦您订阅,就会创建一个 Subscriber 对象链,向后(沿着链向上)到第一个发布者。这对您来说实际上是隐藏的。您所看到的只是 Flux (或 Mono )和 Subscription 的外层,但这些中间operator-specific的订阅者才是真正工作发生的地方。
有了这些知识,我们就可以仔细研究 publishOn 和 subscribeOn 运算符:
publishOn 方法
publishOn 的应用方式与任何其他operator相同,位于subscriber chain的中间。它从上游获取信号并在下游重播它们,同时从关联的 Scheduler 对工作线程执行回调。因此,它会影响后续运算符的执行位置(直到链接另一个 publishOn 为止),如下所示:
- 将执行上下文更改为
Scheduler 选择的Thread - 根据规范, onNext 调用按顺序发生,因此这会占用单个线程
- 除非它们在特定的 Scheduler 上工作,否则 publishOn 之后的运算符将继续在同一线程上执行
以下示例使用 publishOn 方法:
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4);
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) //第一个 map 在行9的匿名线程上运行。
.publishOn(s) //publishOn 将整个序列切换到从行1(s)中选取的 Thread 上。
.map(i -> "value " + i); //第二个 map在行1(s)中选取的Thread上运行。
new Thread(() -> flux.subscribe(System.out::println)); //这个匿名 Thread 是订阅发生的地方。打印发生在最新的执行上下文上,即来自 publishOn 的执行上下文。
subscribeOn 方法
subscribeOn 适用于订阅过程,构建反向链时。通常建议将其放置在数据源之后,因为中间运算符可能会影响执行的上下文。
但是,这不会影响对 publishOn 的后续调用的行为 - 它们仍然会切换其后的链部分的执行上下文。
- 更改whole chain of operators订阅的 Thread
- 从 Scheduler 中选取一个线程
- 注意:只有下游链中最近的
subscribeOn 调用才能有效地将订阅和请求信号调度到可以拦截它们的源或操作员(doFirst 、doOnRequest )。使用多个subscribeOn 调用会引入不必要的没有价值的线程切换。
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4);
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) //第一个 map 在s上
.subscribeOn(s) //因为 subscribeOn 从订阅时间 (行9)开始切换整个序列。
.map(i -> "value " + i); //第二个 map 也在同一线程(s)上运行。
new Thread(() -> flux.subscribe(System.out::println)); //这个匿名 Thread 是订阅最初发生的地方,但 subscribeOn 立即将其转移到四个调度程序线程之一。
处理错误
要快速查看可用于错误处理的运算符,请参阅相关的运算符决策树。see the relevant operator decision tree.
在响应式流中,错误是终端事件。一旦发生错误,它就会停止序列并沿着运算符链传播到最后一步,即您定义的 Subscriber 及其 onError 方法。
此类错误仍应在应用程序级别处理。例如,您可以在 UI 中显示错误通知或在 REST 端点中发送有意义的错误负载。因此,订阅者的 onError 方法应该始终被定义。
- 如果未定义, onError 会抛出 UnsupportedOperationException 。您可以使用 Exceptions.isErrorCallbackNotImplemented 方法进一步检测和分类它。
Reactor 还提供了处理链中间错误的替代方法,如错误处理运算符。以下示例展示了如何执行此操作:
Flux.just(1, 2, 0)
.map(i -> "100 / " + i + " = " + (100 / i)) //this triggers an error with 0
.onErrorReturn("Divided by zero :("); // error handling example
在了解错误处理运算符之前,您必须记住,反应序列中的任何错误都是终止事件。即使使用错误处理运算符,它也不会让原始序列继续。相反,它将 onError 信号转换为新序列(后备序列)的开始。换句话说,它替换了其上游终止的序列。
错误处理运算符
您可能熟悉在 try-catch 块中处理异常的几种方法。所有这些在 Reactor 中都有等价物,以错误处理运算符的形式。在研究这些运算符之前,我们首先要在反应链和 try-catch 块之间建立并行。
订阅时,链末尾的 onError 回调类似于 catch 块。在那里,如果抛出 Exception ,执行会跳到 catch,如以下示例所示:
Flux<String> s = Flux.range(1, 10)
.map(v -> doSomethingDangerous(v)) //执行可能引发异常的转换。
.map(v -> doSecondTransform(v)); //如果一切顺利,就会进行第二次转变。
s.subscribe(value -> System.out.println("RECEIVED " + value), //每个成功转换的值都会被打印出来。
error -> System.err.println("CAUGHT " + error) //如果出现错误,序列将终止并显示错误消息。
);
前面的示例在概念上类似于以下 try-catch 块:
for (int i = 1; i < 11; i++) {
String v1 = doSomethingDangerous(i);
String v2 = doSecondTransform(v1);
System.out.println("RECEIVED " + v2);
}
} catch (Throwable t) {
System.err.println("CAUGHT " + t);
}
static Fallback Value
相当于“捕获并返回静态默认值”的是 onErrorReturn 。以下示例展示了如何使用它:
try {
return doSomethingDangerous(10);
}
catch (Throwable error) {
return "RECOVERED";
}
//以下示例显示了 Reactor 等效项:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");
您还可以选择对异常应用 Predicate 来决定是否恢复,如以下示例所示:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn(e -> e.getMessage().equals("boom10"), "recovered10"); //仅当异常消息为 "boom10" 时才恢复
捕获并吞下错误(Catch and swallow the error)
如果您甚至不想使用回退值(fallback value)替换异常,而是要忽略它,并仅传播到目前为止已经产生的元素,那么您需要的是将onError信号替换为onComplete信号。这可以通过onErrorComplete操作符完成:
Flux.just(10,20,30)
.map(this::doSomethingDangerousOn30)
.onErrorComplete(); //通过将 onError 转换为 onComplete 来恢复
与 onErrorReturn 一样, onErrorComplete 具有变体,可让您根据异常的类或 Predicate 过滤要依赖的异常。
Fallback Method
如果您想要多个默认值并且您有另一种(更安全)的数据处理方式,则可以使用 onErrorResume 。这相当于“使用后备方法捕获并执行替代路径”。
例如,如果您的名义进程正在从外部且不可靠的服务获取数据,但您还保留了相同数据的本地缓存,该数据可能有点过时但更可靠,您可以执行以下操作:
String v1;
try {
v1 = callExternalService("key1");
}
catch (Throwable error) {
v1 = getFromCache("key1");
}
String v2;
try {
v2 = callExternalService("key2");
}
catch (Throwable error) {
v2 = getFromCache("key2");
}
//以下示例显示了 Reactor 等效项:
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(e -> getFromCache(k))
);
与 onErrorReturn 一样, onErrorResume 具有变体,可让您根据异常的类或 Predicate 过滤要依赖的异常。事实上,它需要 Function ,您还可以根据遇到的错误选择不同的后备序列进行切换。以下示例展示了如何执行此操作:
Flux.just("timeout1", "unknown", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(error -> {
if (error instanceof TimeoutException)
return getFromCache(k);
else if (error instanceof UnknownKeyException)
return registerNewEntry(k, "DEFAULT");
else
return Flux.error(error);
})
);
Dynamic Fallback Value 动态回退值
即使您没有替代(更安全)的数据处理方式,您也可能希望从收到的异常中计算回退值。这相当于“捕获并动态计算回退值”。
例如,如果您的返回类型( MyWrapper )有一个专门用于保存异常的变体(例如 Future.complete(T success) 与 Future.completeExceptionally(Throwable error) ),您可以实例化错误保存变体并传递异常。
一个命令式的例子如下所示:
try {
Value v = erroringMethod();
return MyWrapper.fromValue(v);
}
catch (Throwable error) {
return MyWrapper.fromError(error);
}
您可以通过使用 onErrorResume 以及一点样板文件,以与后备方法解决方案相同的方式被动地执行此操作,如下所示:
erroringFlux.onErrorResume(error -> Mono.just(
MyWrapper.fromError(error)
));
Catch and Rethrow 捕获并重新抛出
示例代码如下:
try {
return callExternalService(k);
}
catch (Throwable error) {
throw new BusinessException("oops, SLA exceeded", error);
}
//在“后备方法”示例中, flatMap 内的最后一行提示我们以反应方式实现相同的目标,如下所示:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorResume(original -> Flux.error(
new BusinessException("oops, SLA exceeded", original))
);
//但是,有一种更直接的方法可以使用 onErrorMap 实现相同的效果:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));
Log or React on the Side
如果您希望错误继续传播,但仍希望在不修改序列的情况下对其做出反应(例如记录它),则可以使用 doOnError 运算符。这相当于“捕获、记录特定于错误的消息,然后重新抛出”模式,如以下示例所示:
try {
return callExternalService(k);
}
catch (RuntimeException error) {
//make a record of the error
log("uh oh, falling back, service failed for key " + k);
throw error;
}
doOnError 运算符以及所有以 doOn 为前缀的运算符有时被称为具有“副作用”。它们让您可以查看序列事件的内部情况,而无需修改它们。
与前面显示的命令式示例类似,以下示例仍然传播错误,但确保我们至少记录外部服务发生故障:
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k)
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k);
})
);
Using Resources and the Finally Block
使用命令式编程绘制的最后一个相似之处是清理,可以通过使用“使用 finally 块来清理资源”或使用“Java 7 try-with-resource 构造”来完成”,均如下所示:
Stats stats = new Stats();
stats.startTimer();
try {
doSomethingDangerous();
}
finally {
stats.stopTimerAndRecordTiming();
}
//--------
try (SomeAutoCloseable disposableInstance = new SomeAutoCloseable()) {
return disposableInstance.toString();
}
两者都有其 Reactor 等效项: doFinally 和 using 。
doFinally 是关于您希望在序列终止(使用 onComplete 或 onError )或取消时执行的副作用。它会提示您哪种终止会触发副作用。以下示例展示了如何使用 doFinally :
Stats stats = new Stats();
LongAdder statsCancel = new LongAdder();
Flux<String> flux =
Flux.just("foo", "bar")
.doOnSubscribe(s -> stats.startTimer())
.doFinally(type -> { //doFinally 使用 SignalType 作为终止类型。
stats.stopTimerAndRecordTiming();//与 finally 块类似,我们总是记录时间。
if (type == SignalType.CANCEL) //在这里,我们还仅在取消的情况下增加统计数据。
statsCancel.increment();
})
.take(1); //ake(1) 从上游请求正好 1,并在发出一项后取消。
另一方面, using 处理 Flux 从资源派生的情况,并且每当处理完成时都必须对该资源进行操作。在下面的示例中,我们将“try-with-resource”的 AutoCloseable 接口替换为 Disposable :
AtomicBoolean isDisposed = new AtomicBoolean();
Disposable disposableInstance = new Disposable() {
@Override
public void dispose() {
isDisposed.set(true);
}
@Override
public String toString() {
return "DISPOSABLE";
}
};
现在我们可以对其进行相当于“try-with-resource”的响应式操作,如下所示:
Flux<String> flux =
Flux.using(
() -> disposableInstance, //第一个 lambda 生成资源。在这里,我们返回模拟 Disposable 。
disposable -> Flux.just(disposable.toString()), //第二个 lambda 处理资源,返回 Flux<T> 。
Disposable::dispose //当 <2> 中的 Flux 终止或取消时,将调用第三个 lambda,以清理资源。
);
//简单解释如下:
1. 第一个 lambda 生成资源。在这里,我们返回模拟 Disposable 。
2. 第二个 lambda 处理资源,返回 Flux<T> 。
3. 当Flux 终止或取消时,将调用第三个 lambda,以清理资源。
4. 订阅并执行序列后, isDisposed 原子布尔值变为 true 。
演示 onError
为了证明所有这些运算符在发生错误时都会导致上游原始序列终止,我们可以使用一个更直观的示例 Flux.interval 。 interval 运算符每 x 个时间单位标记一次, Long 值逐渐增加。以下示例使用 interval 运算符:
Flux<String> flux =
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.onErrorReturn("Uh oh");
flux.subscribe(System.out::println);
Thread.sleep(2100);
//输出:
tick 0
tick 1
tick 2
Uh oh
请注意,默认情况下 interval 在计时器 Scheduler 上执行。如果我们想在主类中运行该示例,则需要在此处添加 sleep 调用,以便应用程序不会在没有产生任何值的情况下立即退出。
重试
关于错误处理还有另一个令人感兴趣的运算符,您可能会想在上一节中描述的情况下使用它。 retry ,正如其名称所示,允许您重试产生错误的序列。
需要记住的是,它是通过重新订阅上游 Flux 来工作的。这确实是一个不同的序列,并且原始序列仍然终止。为了验证这一点,我们可以重新使用前面的示例并附加 retry(1) 来重试一次,而不是使用 onErrorReturn 。以下示例展示了如何执行此操作:
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.retry(1)
.elapsed() //elapsed 将每个值与自发出前一个值以来的持续时间相关联。
.subscribe(System.out::println, System.err::println);
Thread.sleep(2100);
//输出
259,tick 0
249,tick 1
251,tick 2
506,tick 0 //新的 interval 从刻度 0 开始。额外的 250 毫秒持续时间来自第四个刻度,即导致异常和后续重试的刻度。
248,tick 1
253,tick 2
java.lang.RuntimeException: boom
从上面的例子可以看出, retry(1) 只是重新订阅了原来的 interval 一次,从0重新开始tick。第二次,由于仍然出现异常,所以放弃并向下游传播错误。
有一个更高级的 retry 版本(称为 retryWhen ),它使用“同伴” Flux 来判断特定故障是否应该重试。这个同伴 Flux 由operator创建,但由用户修饰,以便自定义重试条件。
伴随 Flux 是一个 Flux<RetrySignal> ,它被传递给 Retry 策略/函数,作为 retryWhen 的唯一参数提供。作为用户,您定义该函数并使其返回新的 Publisher<?> 。 Retry 类是一个抽象类,但如果您想使用简单的 lambda ( Retry.from(Function) ) 转换伴生类,它提供了一个工厂方法。
重试周期如下:
- 每次发生错误(可能会重试)时,都会将
RetrySignal 发送到已由您的函数修饰的同伴Flux 中。这里有Flux 可以让您鸟瞰迄今为止的所有尝试。RetrySignal 允许访问错误及其周围的元数据。 - 如果同伴
Flux 发出一个值,则会发生重试。 - 如果伴随
Flux 完成,则错误被吞掉,重试周期停止,并且生成的序列也完成。 - 如果伴随
Flux 产生错误 (e ),则重试周期将停止,并且生成的序列错误e 。
前两种情况的区别很重要。简单地完成同伴就可以有效地消除错误。考虑使用 retryWhen 模拟 retry(3) 的以下方法:
Flux<String> flux = Flux
.<String>error(new IllegalArgumentException()) //这会不断产生错误,需要重试。
.doOnError(System.out::println) //doOnError 在重试之前,我们可以记录并查看所有失败。
.retryWhen(Retry.from(companion -> //Retry 改编自一个非常简单的 Function lambda
companion.take(3))); //在这里,我们认为前三个错误是可以重试的 ( take(3) ),然后放弃。
人们可以使用 Retry 中公开的构建器以更流畅的方式以及更精细调整的重试策略来实现相同的目的。例如: errorFlux.retryWhen(Retry.max(3)); 。
指数退避和重试的一个示例:
AtomicInteger errorCount = new AtomicInteger();
Flux<String> flux =
Flux.<String>error(new IllegalStateException("boom"))
.doOnError(e -> {
errorCount.incrementAndGet();
System.out.println(e + " at " + LocalTime.now());
})
.retryWhen(Retry
.backoff(3, Duration.ofMillis(100)).jitter(0d)
.doAfterRetry(rs -> System.out.println("retried at " + LocalTime.now() + ", attempt " + rs.totalRetries()))
.onRetryExhaustedThrow((spec, rs) -> rs.failure())
);
//输出
java.lang.IllegalStateException: boom at 00:00:00.0
retried at 00:00:00.101, attempt 0
java.lang.IllegalStateException: boom at 00:00:00.101
retried at 00:00:00.304, attempt 1
java.lang.IllegalStateException: boom at 00:00:00.304
retried at 00:00:00.702, attempt 2
java.lang.IllegalStateException: boom at 00:00:00.702
核心提供的 Retry 帮助器 RetrySpec 和 RetryBackoffSpec 都允许高级自定义,例如:
- 设置
filter(Predicate) 为可以触发重试的异常 - 通过
modifyErrorFilter(Function) 修改先前设置的过滤器 - 触发副作用,例如围绕重试触发器进行记录(即延迟之前和之后的退避),前提是重试已验证( doBeforeRetry() 和 doAfterRetry() 是累加的)
- 围绕重试触发器触发异步
Mono<Void> ,这允许在基本延迟之上添加异步行为,从而进一步延迟触发器(doBeforeRetryAsync 和doAfterRetryAsync 是添加剂) - 通过
onRetryExhaustedThrow(BiFunction) 自定义达到最大尝试次数时的异常。默认使用Exceptions.retryExhausted(…) ,可以与Exceptions.isRetryExhausted(Throwable) 区分
重试偶发性错误
针对一些偶发性错误,最好单独处理每个突发,以便下一个突发不会继承前一个突发的重试状态。例如,使用指数退避策略,每个后续突发都应该从最小退避 Duration 开始延迟重试尝试,而不是不断增长的退避。
表示 retryWhen 状态的 RetrySignal 接口有一个可用于此目的的 totalRetriesInARow() 值。与通常单调递增的 totalRetries() 索引不同,每次重试恢复错误时(即,当重试尝试导致传入 onNext 再次代替 onError )
The
RetrySignal interface, which representsretryWhen state, has atotalRetriesInARow() value which can be used for this. Instead of the usual monotonically-increasingtotalRetries() index, this secondary index is reset to 0 each time an error is recovered from by the retry (ie. when a retry attempt results in an incomingonNext instead of anonError again).
将 RetrySpec 或 RetryBackoffSpec 中的 transientErrors(boolean) 配置参数设置为 true 时,生成的策略将使用该 totalRetriesInARow()
AtomicInteger errorCount = new AtomicInteger();
Flux<Integer> transientFlux = httpRequest.get() //我们假设一个http请求源,例如。流端点有时会连续失败两次,然后恢复。
.doOnError(e -> errorCount.incrementAndGet());
transientFlux.retryWhen(Retry.max(2).transientErrors(true)) //我们在该源上使用 retryWhen ,配置为最多 2 次重试尝试,但处于 transientErrors 模式。
.blockLast();
assertThat(errorCount).hasValue(6); //如果没有 transientErrors(true) ,第二个突发将超过 2 配置的最大尝试,整个序列最终将失败。
如果您想在没有实际 http 远程端点的情况下在本地尝试此操作,可以将伪 httpRequest 方法实现为 Supplier ,如下所示:
final AtomicInteger transientHelper = new AtomicInteger();
Supplier<Flux<Integer>> httpRequest = () ->
Flux.generate(sink -> { //我们 generate 一个有大量错误的来源。
int i = transientHelper.getAndIncrement();
if (i == 10) {
sink.next(i);
sink.complete();
}
else if (i % 3 == 0) {
sink.next(i);
}
else {
sink.error(new IllegalStateException("Transient error at " + i));
}
});
处理运算符或函数中的异常
一般来说,所有运算符本身都可以包含可能触发异常的代码或调用可能同样失败的用户定义回调,因此它们都包含某种形式的错误处理。
根据经验,未经检查的异常始终通过 onError 传播。例如,在 map 函数内抛出 RuntimeException 会转换为 onError 事件,如以下代码所示:
Flux.just("foo")
.map(s -> { throw new IllegalArgumentException(s); })
.subscribe(v -> System.out.println("GOT VALUE"),
e -> System.out.println("ERROR: " + e));
//输出
ERROR: java.lang.IllegalArgumentException: foo
然而,Reactor 定义了一组始终被视为致命的异常(例如 OutOfMemoryError )。请参阅 Exceptions.throwIfFatal 方法。这些错误意味着 Reactor 无法继续运行,并且会被抛出而不是传播。
在内部,还存在未经检查的异常仍然无法传播的情况(最明显的是在订阅和请求阶段),因为并发竞争可能导致双重 onError 或 onComplete 条件。当这些竞争发生时,无法传播的错误将被“丢弃”。
针对checked exception,例如,如果您需要调用一些将其声明为 throws 异常的方法,那么您仍然必须在 try-catch 块中处理这些异常。不过,您有多种选择:
- 捕获异常并从中恢复。该序列正常继续。
- 捕获异常,将其包装成未经检查的异常,然后抛出它(中断序列)。 Exceptions 实用程序类可以帮助您完成此任务(我们接下来会介绍)。
- 如果您需要返回 Flux (例如,您位于 flatMap 中),请将异常包装在产生错误的 Flux 中(该序列也终止。)
Reactor 有一个 Exceptions 实用程序类,您可以使用它来确保仅当异常是已检查异常时才包装异常:
- 如有必要,请使用 Exceptions.propagate 方法来包装异常。它还首先调用 throwIfFatal 并且不包装 RuntimeException 。
- 使用 Exceptions.unwrap 方法获取原始未包装的异常(回到特定于反应器的异常层次结构的根本原因)。
考虑以下 map 示例,该示例使用可以抛出 IOException 的转换方法:
public String convert(int i) throws IOException {
if (i > 3) {
throw new IOException("boom " + i);
}
return "OK " + i;
}
现在假设您想在 map 中使用该方法。您现在必须显式捕获异常,并且您的映射函数无法重新抛出该异常。因此,您可以将其作为 RuntimeException 传播到map的 onError 方法,如下所示:
Flux<String> converted = Flux
.range(1, 10)
.map(i -> {
try { return convert(i); }
catch (IOException e) { throw Exceptions.propagate(e); }
});
稍后,当订阅前面的 Flux 并对错误做出反应(例如在 UI 中)时,如果您想对 IOException 执行一些特殊操作,则可以恢复到原始异常。以下示例展示了如何执行此操作:
converted.subscribe(
v -> System.out.println("RECEIVED: " + v),
e -> {
if (Exceptions.unwrap(e) instanceof IOException) {
System.out.println("Something bad happened with I/O");
} else {
System.out.println("Something bad happened");
}
}
);
Sinks
在 Reactor 中,接收器是一个类,它允许以独立的方式安全地手动触发信号,创建一个类似 Publisher 的结构,能够处理多个 Subscriber ( unicast() 口味)。
使用 Sinks.One 和 Sinks.Many 从多个线程安全地生成
reactor-core默认的Sink确保多线程使用被检测到,并且不能导致下游订阅者在规范违规或未定义行为方面出现问题。在使用tryEmit* API时,并发调用会快速失败。在使用emit* API时,提供的EmissionFailureHandler可能会允许在争用时重试(例如繁忙循环),否则Sink将以错误终止。
这是对 Processor.onNext 的改进,后者必须在外部同步,否则从下游订阅者的角度来看会导致未定义的行为。
Sinks 构建器为主要支持的生产者类型提供指导 API。您将识别 Flux 中发现的一些行为,例如 onBackpressureBuffer 。
Sinks.Many<Integer> replaySink = Sinks.many().replay().all();
多个生产者线程可以通过执行以下操作同时在接收器上生成数据:
//thread1
replaySink.emitNext(1, EmitFailureHandler.FAIL_FAST);
//thread2, later
replaySink.emitNext(2, EmitFailureHandler.FAIL_FAST);
//thread3, concurrently with thread 2
//would retry emitting for 2 seconds and fail with EmissionException if unsuccessful
replaySink.emitNext(3, EmitFailureHandler.busyLooping(Duration.ofSeconds(2)));
//thread3, concurrently with thread 2
//would return FAIL_NON_SERIALIZED
EmitResult result = replaySink.tryEmitNext(4);
使用 busyLooping 时,请注意 EmitFailureHandler 返回的实例不能重复使用,例如,每个 emitNext
Sinks.Many 可以作为 Flux 呈现给下游消费者,如下例所示:
Flux<Integer> fluxView = replaySink.asFlux();
fluxView
.takeWhile(i -> i < 10)
.log()
.blockLast();
类似地, Sinks.Empty 和 Sinks.One 风格可以被视为具有 asMono() 方法的 Mono 。
Sinks 类别是:
- many().multicast() :一个接收器,仅将新推送的数据传输给其订阅者,尊重他们的背压(新推送的数据如“订阅者订阅后”)。
- many().unicast() :与上面相同,但在第一个订阅者寄存器之前推送的数据被缓冲。
- many().replay() :一个接收器,它将向新订阅者重播指定历史大小的推送数据,然后继续实时推送新数据。
- one() :将向其订阅者播放单个元素的接收器
- empty() :一个接收器,仅向其订阅者播放终端信号(错误或完成),但仍然可以被视为
Mono<T>(注意通用类型<T>
Overview of Available Sinks
Sinks.many().unicast().onBackpressureBuffer(args?)
单播 Sinks.Many 可以通过使用内部缓冲区来处理背压。权衡是它最多可以有一个 Subscriber 。
基本单播接收器是通过 Sinks.many().unicast().onBackpressureBuffer() 创建的。但是 Sinks.many().unicast() 中还有一些额外的 unicast 静态工厂方法,可以进行更精细的调整。
例如,默认情况下,它是无界的:如果您通过它推送任意数量的数据,而它的 Subscriber 尚未请求数据,它会缓冲所有数据。您可以通过在 Sinks.many().unicast().onBackpressureBuffer(Queue) 工厂方法中为内部缓冲提供自定义 Queue 实现来更改此设置。如果该队列是有界的,则当缓冲区已满并且没有收到来自下游的足够请求时,接收器可能会拒绝推送值。
Sinks.many().multicast().onBackPressureBuffer(args?)
多播 Sinks.Many 可以向多个订阅者发送消息,同时为其每个订阅者提供背压。订阅者在订阅后仅接收通过接收器推送的信号。
基本多播接收器是通过 Sinks.many().multicast().onBackpressureBuffer() 创建的。
默认情况下,如果所有订阅者都被取消(这基本上意味着它们都已取消订阅),它将清除其内部缓冲区并停止接受新订阅者。您可以通过使用 Sinks.many().multicast() 下的 multicast 静态工厂方法中的 autoCancel 参数来调整它。
Sinks.many().multicast().directAllOrNothing()
具有简单化背压处理的多播 Sinks.Many :如果任何订阅者太慢(需求为零),则所有订阅者的 onNext 都会被丢弃。
然而,慢速订阅者不会被终止,一旦慢速订阅者再次开始请求,所有订阅者都将恢复接收从那里推送的元素。
一旦 Sinks.Many 终止(通常通过调用其 emitError(Throwable) 或 emitComplete() 方法),它会让更多订阅者订阅,但立即向他们重播终止信号。
Sinks.many().multicast().directBestEffort()
尽力处理背压的多播 Sinks.Many :如果订阅者太慢(需求为零),则仅针对该慢速订阅者丢弃 onNext 。
然而,慢速订阅者不会被终止,一旦他们再次开始请求,他们将恢复接收新推送的元素。
一旦 Sinks.Many 终止(通常通过调用其 emitError(Throwable) 或 emitComplete() 方法),它会让更多订阅者订阅,但立即向他们重播终止信号。
Sinks.many().replay()
重播 Sinks.Many 缓存发出的元素并将其重播给迟到的订阅者。
它可以以多种配置创建:
- 缓存有限历史记录 (
Sinks.many().replay().limit(int) ) 或无限历史记录 (Sinks.many().replay().all() )。 - 缓存基于时间的重播窗口 ( Sinks.many().replay().limit(Duration) )。
- 缓存历史记录大小和时间窗口的组合 (
Sinks.many().replay().limit(int, Duration) )。
用于微调上述内容的其他重载也可以在 Sinks.many().replay() 下找到,以及允许缓存单个元素的变体( latest() 和 latestOrDefault(T) ) 。
Sinks.unsafe().many()
高级用户和操作员构建者可能会考虑使用 Sinks.unsafe().many() ,它将提供相同的 Sinks.Many 工厂,而无需额外的生产者线程安全性。因此,每个接收器的开销会更少,因为线程安全接收器必须检测多线程访问。
库开发人员不应公开不安全的接收器,但可以在受控的调用环境中内部使用它们,在该环境中他们可以确保导致 onNext 、 onComplete 和 onError
Sinks.one()
该方法直接构造一个简单的 Sinks.One<T> 实例。 Sinks 的这种风格可以作为 Mono 查看(通过其 asMono() 视图方法),并且具有稍微不同的 emit 方法来更好地传达这种类似 Mono 的语义:
- emitValue(T value) 生成 onNext(value) 信号,并且在大多数实现中 - 还将触发隐式 onComplete()
- emitEmpty() 生成一个隔离的 onComplete() 信号,旨在生成空 Mono 的等效信号
- emitError(Throwable t) 生成 onError(t) 信号
Sinks.one() 接受对这些方法中任何一个的一次调用,有效地生成一个 Mono ,该 Mono 要么以一个值完成,要么以空完成或失败。
Sinks.empty()
该方法直接构造一个简单的 Sinks.Empty<T> 实例。 Sinks 的这种风格类似于 Sinks.One<T> ,只是它不提供 emitValue 方法。结果,它只能生成一个完成为空或失败的 Mono 。尽管无法触发 onNext ,接收器仍然使用通用 <T> 进行类型化,因为它允许轻松组合和包含在需要特定类型的运算符链中。
版权申明
本站点所有内容,版权均归https://wenchao.ren所有,除非明确授权,否则禁止一切形式的转载协议
打赏


