确保数据落盘
确保数据落盘
在之前的文章《unix IO模型》我们曾经提到过,用户空间,内核空间,缓存IO等概念。关于这些概念,大家可以阅读这篇文章,在本篇文章中,我们就不在涉及这些概念了。
IO缓冲机制
大家需要有一个认知就是我们平时写的程序,在将数据到文件中时,其实数据不会立马写入磁盘中进行持久化存储的,而是会经过层层缓存,如下图所示:
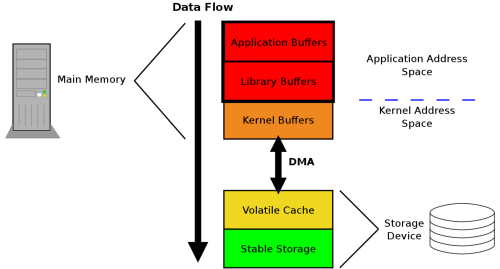
其中这每层缓存都有自己的刷新时机,每层缓存都刷新后才会写入磁盘进行持久化存储。这些缓存的存在目的本意都是为了加速读写操作,因为如果每次读写都对应真实磁盘操作,那么读写的效率会大大降低。但是同样带来的坏处是如果期间发生掉电或者别的故障,还未写入磁盘的数据就丢失了。对于数据安全敏感的应用,比如数据库,比如交易程序,这是无法忍受的。所以操作系统提供了保证文件落盘的机制。
在上面这图中说明了操作系统到磁盘的数据流,以及经过的缓冲区。首先数据会先存在于应用的内存空间,如果调用库函数写入,库函数可能还会把数据缓存在库函数所维护的缓冲区空间中,比如C标准库stdio提供的方法就会进行缓存,目的是为了减少系统调用的次数。这两个缓存都是在用户空间中的。库函数缓存flush时,会调用write系统调用将数据写入内核空间,内核同样维护了一个页缓存(page cache),操作系统会在合适的时间把脏页的数据写入磁盘。即使是写入磁盘了,磁盘也可能维护了一个缓存,在这个时候掉电依然会丢失数据的,只有写入了磁盘的持久存储物理介质上,数据才是真正的落盘了,是安全的。
比如在网络套接字上侦听连接并将从每个客户端接收的数据写入文件的应用程序。 在关闭连接之前,服务器确保将接收到的数据写入稳定存储器,并向客户端发送此类确认,请看下面的简化代码(代码中已经注释):
int sock_read(int sockfd, FILE *outfp, size_t nrbytes)
{
int ret;
size_t written = 0;
//example of an application buffer
char *buf = malloc(MY_BUF_SIZE);
if (!buf)
return -1;
//take care of reading the data from the socket
//and writing it to the file stream
while (written < nrbytes) {
ret = read(sockfd, buf, MY_BUF_SIZE);
if (ret =< 0) {
if (errno == EINTR)
continue;
return ret;
}
written += ret;
ret = fwrite((void *)buf, ret, 1, outfp);
if (ret != 1)
return ferror(outfp);
}
//flush file stream, the data to move into the "Kernel Buffers" layer
ret = fflush(outfp);
if (ret != 0)
return -1;
//makethe data is saved to the "Stable Storage" layer
ret = fsync(fileno(outfp));
if (ret < 0)
return -1;
return 0;
}
在上面的这幅图中,可以看到数据流向经过了用户控件缓冲区和内核缓存区,下面我们说说这2个缓存区。
用户空间缓冲区
用户空间的缓存分为:
- 应用程序本身维护的缓冲区
- 库维护的缓冲区
应用本身维护的缓冲区需要开发者自己刷新,调用库函数写入到库函数的缓冲区中(这一步可能不存在)。如果应用程序不依赖任何库函数,而是直接使用系统调用,那么则是把数据写入系统的缓冲区去。
库函数一般都会维护缓冲区,目的是简化应用程序的编写,应用程序就不需要编写维护缓冲区的代码,库维护的缓冲区针对那些没有应用程序本身维护的缓存区的程序来说,在某些时候是会提升不少的性能的,因为缓冲区大大减少了系统调用的次数,而系统调用是非常耗时的,系统调用涉及到用户态到内核态的切换,这个切换需要很多的步骤与校验,较为耗时。
比如C标准库stdio就维护着一个缓冲区,对应这个缓冲区,C标准库提供了fflush方法强制把缓冲区数据写入操作系统。
在Java的OutputStream接口提供了一个flush方法,具体的作用要看实现类的具体实现。BufferedOutputStream#flush就会把自己维护的缓冲区数据写入下一层的OutputStream。比如是new BufferedOutputStream(new FileOutputStream("/"))这样的模式,则调用BufferedOutputStream#flush会将数据写入操作系统。
内核缓冲区
应用程序直接或者通过库函数间接的使用系统调用write将数据写入操作系统缓冲区.UNIX系统在内核中设有高速缓存或页面高速缓存。目的是为了减少磁盘读写次数。
用户写入系统的数据先写入系统缓冲区,系统缓冲区写满后,将其排入输出队列,然后得到队首时,才进行实际的IO操作。这种输出方式被称为延迟写。
UNIX系统提供了三个系统调用来执行刷新内核缓冲区:sync,fsync,fdatasync。
sync
// sync() causes all pending modifications to filesystem metadata and
//cached file data to be written to the underlying filesystems.
void sync(void)
sync函数只是将所有修改过的块缓冲区排入输出队列就返回,并不等待实际的写磁盘操作返回。 操作系统的update系统守护进程会周期地调用sync函数,来保证系统中的数据能定期落盘。
根据sync(2) - Linux manual page的描述,Linux对sync的实现与POSIX规范不太一样,POSIX规范中,sync可能在文件真正落盘前就返回,而Linux的实现则是文件真正落盘后才会返回。所以Linux中,sync与fsync的效果是一样的!但是1.3.20之前的Linux存在BUG,导致sync并不会在真正落盘后返回。
fsync
void fsync(int filedes)
fsync对指定的文件起作用,它传输内核缓冲区中这个文件的数据到存储设备中,并阻塞直到存储设备响应说数据已经保存好了。
fsync对文件数据与文件元数据都有效。文件的元数据可以理解为文件的属性数据,比如文件的更新时间,访问时间,长度等。
fdatasync
void fdatasync(int filedes)
fdatasync和fsync类似,两者的区别是,fdatasync不一定需要刷新文件的元数据部分到存储设备。
是否需要刷新文件的元数据,是要看元数据的变化部分是否对之后的读取有影响,比如文件元数据的访问时间st_atime和修改时间st_mtime变化了,fdatasync不会去刷新元数据数据到存储设备,因为即使这个数据丢失了不一致了,也不影响故障恢复后的文件读取。但是如果文件的长度st_size变化了,那么就需要刷新元数据数据到存储设备。
所以如果你每次都更新文件长度,那么调用fsync和fdatasync的效果是一样的。
但是如果更新能做到不修改文件长度,那么fdatasync能比fsync少了一次磁盘写入,这个是非常大的速度提升。
open中的O_SYNC和O_DSYNC
除了上面三个系统调用,open系统调用在打开文件时,可以设置和同步相关的标志位:O_SYNC和O_DSYNC。
- 设置O_SYNC的效果相当于是每次write后自动调用fsync。
- 设置O_DSYNC的效果相当于是每次write后自动调用fdatasync。
关于新建文件
在一个文件上调用fsync/fdatasync只能保证文件本身的数据落盘,但是对于文件系统来说,目录中也保存着文件信息,fsync/fdatasync的调用并不会保证这部分的数据落盘。如果此时发生掉电,这个文件就无法被找到了。所以对于新建文件来说,还需要在父目录上调用fsync。
关于覆盖现有文件
覆盖现有文件时,如果发生掉电,新的数据是不会写入成功,但是可能会污染现有的数据,导致现有数据丢失。所以最佳实践是新建一个临时文件,写入成功后,再原子性替换原有文件。具体步骤:
- 新建一个临时文件
- 向临时文件写入数据
- 对临时文件调用fsync,保证数据落盘。期间发生掉电对现有文件无影响。
- 重命名临时文件为目标文件名
- 对父目录调用fsync
存储设备缓冲区
存储设备为了提高性能,也会加入缓存。高级的存储设备能提供非易失性的缓存,比如有掉电保护的缓存。但是无法对所有设备做出这种保证,所以如果数据只是写入了存储设备的缓存的话,遇到掉电等故障,依然会导致数据丢失。
对于保证数据能保存到存储设备的持久化存储介质上,而不管设备本身是否有易失性缓存,操作系统提供了write barriers这个机制。开启了write barriers的文件系统,能保证调用fsync/fdatasync数据持久化保存,无论是否发生了掉电等其他故障,但是会导致性能下降。
许多文件系统提供了配置write barriers的功能。比如ext3, ext4, xfs 和 btrfs。mount参数-o barrier表示开启写屏障,调用fsync/fdatasync能保证刷新存储设备的缓存到持久化介质上。-o nobarrier则表示关闭写屏障,调用fsync/fdatasync无法保证数据落盘。
Linux默认开启write barriers,所以默认情况下,我们调用fsync/fdatasync,就可以认为是文件真正的可靠落盘了。
对于这个层面的数据安全保证来说,应用程序是不需要去考虑的,因为如果这台机器的硬盘被挂载为没有开启写屏障,那么可以认为这个管理员知道这个风险,他选择了更高的性能,而不是更高的安全性。
Java世界中的对应API
针对确保数据落盘,掉电也不丢失数据的情况,JDK也封装了对应的功能,并且为我们做好了跨平台的保证。
JDK中有三种方式可以强制文件数据落盘:
- 调用
FileDescriptor#sync函数 - 调用
FileChannel#force函数 - 使用
RandomAccessFile以rws或者rwd模式打开文件
FileDescriptor#sync
FileDescriptor类提供了sync方法,可以用于保证数据保存到持久化存储设备后返回。使用方法:
FileOutputStream outputStream = new FileOutputStream("/Users/mazhibin/b.txt");
outputStream.getFD().sync();
可以看一下JDK是如何实现FileDescriptor#sync的:
public native void sync() throws SyncFailedException;
// jdk/src/solaris/native/java/io/FileDescriptor_md.c
JNIEXPORT void JNICALL
Java_java_io_FileDescriptor_sync(JNIEnv *env, jobject this) {
// 获取文件描述符
FD fd = THIS_FD(this);
// 调用IO_Sync来执行数据同步
if (IO_Sync(fd) == -1) {
JNU_ThrowByName(env, "java/io/SyncFailedException", "sync failed");
}
}
// IO_Sync在UNIX系统上的定义就是fsync:
// jdk/src/solaris/native/java/io/io_util_md.h
#define IO_Sync fsync
FileChannel#force
之前的文章提到了,操作系统提供了fsync/fdatasync两个用户同步数据到持久化设备的系统调用,后者尽可能的会不同步文件元数据,来减少一次磁盘IO,提高性能。但是Java IO的FileDescriptor#sync只是对fsync的封装,JDK中没有对于fdatasync的封装,这是一个特性缺失。
Java NIO对这一点也做了增强,FileChannel类的force方法,支持传入一个布尔参数metaData,表示是否需要确保文件元数据落盘,如果为true,则调用fsync。如果为false,则调用fdatasync。
使用例子如下:
FileOutputStream outputStream = new FileOutputStream("/Users/mazhibin/b.txt");
// 强制文件数据与元数据落盘
outputStream.getChannel().force(true);
// 强制文件数据落盘,不关心元数据是否落盘
outputStream.getChannel().force(false);
在jdk中的实现如下:
public class FileChannelImpl extends FileChannel {
private final FileDispatcher nd;
private final FileDescriptor fd;
private final NativeThreadSet threads = new NativeThreadSet(2);
public final boolean isOpen() {
return open;
}
private void ensureOpen() throws IOException {
if(!this.isOpen()) {
throw new ClosedChannelException();
}
}
// 布尔参数metaData用于指定是否需要文件元数据也确保落盘
public void force(boolean metaData) throws IOException {
// 确保文件是已经打开的
ensureOpen();
int rv = -1;
int ti = -1;
try {
begin();
ti = threads.add();
// 再次确保文件是已经打开的
if (!isOpen())
return;
do {
// 调用FileDispatcher#force
rv = nd.force(fd, metaData);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
} finally {
threads.remove(ti);
end(rv > -1);
assert IOStatus.check(rv);
}
}
}
实现中有许多线程同步相关的代码,不属于我们要关注的部分,就不分析了。FileChannel#force调用FileDispatcher#force。FileDispatcher是NIO内部实现用的一个类,封装了一些文件操作方法,其中包含了刷新文件的方法:
abstract class FileDispatcher extends NativeDispatcher {
abstract int force(FileDescriptor fd, boolean metaData) throws IOException;
// ...
}
FileDispatcher#force的实现:
class FileDispatcherImpl extends FileDispatcher {
int force(FileDescriptor fd, boolean metaData) throws IOException {
return force0(fd, metaData);
}
static native int force0(FileDescriptor fd, boolean metaData) throws IOException;
// ...
FileDispatcher#force的本地方法实现:
JNIEXPORT jint JNICALL
Java_sun_nio_ch_FileDispatcherImpl_force0(JNIEnv *env, jobject this,
jobject fdo, jboolean md)
{
// 获取文件描述符
jint fd = fdval(env, fdo);
int result = 0;
if (md == JNI_FALSE) {
// 如果调用者认为不需要同步文件元数据,调用fdatasync
result = fdatasync(fd);
} else {
#ifdef _AIX
/* On AIX, calling fsync on a file descriptor that is opened only for
* reading results in an error ("EBADF: The FileDescriptor parameter is
* not a valid file descriptor open for writing.").
* However, at this point it is not possibly anymore to read the
* 'writable' attribute of the corresponding file channel so we have to
* use 'fcntl'.
*/
int getfl = fcntl(fd, F_GETFL);
if (getfl >= 0 && (getfl & O_ACCMODE) == O_RDONLY) {
return 0;
}
#endif
// 如果调用者认为需要同步文件元数据,调用fsync
result = fsync(fd);
}
return handle(env, result, "Force failed");
}
可以看出,其实FileChannel#force就是简单的通过metaData参数来区分调用fsync和fdatasync。
同时在zookeeper的org.apache.zookeeper.common.AtomicFileOutputStream类中我们可以看到下面的代码:
@Override
public void close() throws IOException {
boolean triedToClose = false, success = false;
try {
flush();
((FileOutputStream) out).getChannel().force(true);
triedToClose = true;
super.close();
success = true;
} finally {
if (success) {
boolean renamed = tmpFile.renameTo(origFile);
if (!renamed) {
// On windows, renameTo does not replace.
if (!origFile.delete() || !tmpFile.renameTo(origFile)) {
throw new IOException(
"Could not rename temporary file " + tmpFile
+ " to " + origFile);
}
}
} else {
if (!triedToClose) {
// If we failed when flushing, try to close it to not leak
// an FD
IOUtils.closeStream(out);
}
// close wasn't successful, try to delete the tmp file
if (!tmpFile.delete()) {
LOG.warn("Unable to delete tmp file " + tmpFile);
}
}
}
}
RandomAccessFile结合rws/rwd模式
RandomAccessFile打开文件支持4中模式:
r以只读方式打开。调用结果对象的任何 write 方法都将导致抛出 IOException。rw打开以便读取和写入。如果该文件尚不存在,则尝试创建该文件。rws打开以便读取和写入,对于rws,还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备。rwd打开以便读取和写入,对于rwd,还要求对文件内容的每个更新都同步写入到底层存储设备。
其中rws模式会在open文件时传入O_SYNC标志位。rwd模式会在open文件时传入O_DSYNC标志位。
RandomAccessFile源码如下:
// 4个标志位,用于组合表示4种模式
private static final int O_RDONLY = 1;
private static final int O_RDWR = 2;
private static final int O_SYNC = 4;
private static final int O_DSYNC = 8;
public RandomAccessFile(File file, String mode)
throws FileNotFoundException
{
String name = (file != null ? file.getPath() : null);
int imode = -1;
// 只读模式
if (mode.equals("r"))
imode = O_RDONLY;
else if (mode.startsWith("rw")) {
// 读写模式
imode = O_RDWR;
rw = true;
// 读写模式下,可以结合O_SYNC和O_DSYNC标志
if (mode.length() > 2) {
if (mode.equals("rws"))
imode |= O_SYNC;
else if (mode.equals("rwd"))
imode |= O_DSYNC;
else
imode = -1;
}
}
if (imode < 0)
throw new IllegalArgumentException("Illegal mode \"" + mode
+ "\" must be one of "
+ "\"r\", \"rw\", \"rws\","
+ " or \"rwd\"");
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
if (rw) {
security.checkWrite(name);
}
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
// 新建文件描述符
fd = new FileDescriptor();
fd.attach(this);
path = name;
open(name, imode);
}
private void open(String name, int mode)
throws FileNotFoundException {
open0(name, mode);
}
private native void open0(String name, int mode)
throws FileNotFoundException;
其中open0的实现为:
// jdk/src/share/native/java/io/RandomAccessFile.c
JNIEXPORT void JNICALL
Java_java_io_RandomAccessFile_open0(JNIEnv *env,
jobject this, jstring path, jint mode)
{
int flags = 0;
// JAVA中的标志位与操作系统标志位转换
if (mode & java_io_RandomAccessFile_O_RDONLY)
flags = O_RDONLY;
else if (mode & java_io_RandomAccessFile_O_RDWR) {
flags = O_RDWR | O_CREAT;
if (mode & java_io_RandomAccessFile_O_SYNC)
flags |= O_SYNC;
else if (mode & java_io_RandomAccessFile_O_DSYNC)
flags |= O_DSYNC;
}
// 调用fileOpen打开函数
fileOpen(env, this, path, raf_fd, flags);
}
fileOpen之后的流程与FileInputStream的一致。可以看出,相比于FileInputStream固定使用O_RDONLY,FileOutputStream固定使用O_WRONLY | O_CREAT,RandomAccessFile提供了在Java中指定打开模式的能力。
但是同时我们需要清除,rws和rwd的效率比rw低非常非常多,因为每次读写都需要刷到磁盘才会返回,这两个中rwd比rws效率高一些,因为rwd只刷新文件内容,rws刷新文件内容与元数据,文件的元数据就是文件更新时间等信息。
原子性的重命名文件
在java中的File类的renameTo方法,提供了重命名文件的功能。但是需要注意的是这个方法并不能保证原子性。
/**
* Renames the file denoted by this abstract pathname.
*
* <p> Many aspects of the behavior of this method are inherently
* platform-dependent: The rename operation might not be able to move a
* file from one filesystem to another, it might not be atomic, and it
* might not succeed if a file with the destination abstract pathname
* already exists. The return value should always be checked to make sure
* that the rename operation was successful.
*
* <p> Note that the {@link java.nio.file.Files} class defines the {@link
* java.nio.file.Files#move move} method to move or rename a file in a
* platform independent manner.
*
* @param dest The new abstract pathname for the named file
*
* @return <code>true</code> if and only if the renaming succeeded;
* <code>false</code> otherwise
*
* @throws SecurityException
* If a security manager exists and its <code>{@link
* java.lang.SecurityManager#checkWrite(java.lang.String)}</code>
* method denies write access to either the old or new pathnames
*
* @throws NullPointerException
* If parameter <code>dest</code> is <code>null</code>
*/
public boolean renameTo(File dest) {
因此如果想原子性的重命名和移动文件,我们应该使用java.nio.file.Files类中的move方法:
/**
* Move or rename a file to a target file.
*
* <p> By default, this method attempts to move the file to the target
* file, failing if the target file exists except if the source and
* target are the {@link #isSameFile same} file, in which case this method
* has no effect. If the file is a symbolic link then the symbolic link
* itself, not the target of the link, is moved. This method may be
* invoked to move an empty directory. In some implementations a directory
* has entries for special files or links that are created when the
* directory is created. In such implementations a directory is considered
* empty when only the special entries exist. When invoked to move a
* directory that is not empty then the directory is moved if it does not
* require moving the entries in the directory. For example, renaming a
* directory on the same {@link FileStore} will usually not require moving
* the entries in the directory. When moving a directory requires that its
* entries be moved then this method fails (by throwing an {@code
* IOException}). To move a <i>file tree</i> may involve copying rather
* than moving directories and this can be done using the {@link
* #copy copy} method in conjunction with the {@link
* #walkFileTree Files.walkFileTree} utility method.
*
* <p> The {@code options} parameter may include any of the following:
*
* <table border=1 cellpadding=5 summary="">
* <tr> <th>Option</th> <th>Description</th> </tr>
* <tr>
* <td> {@link StandardCopyOption#REPLACE_EXISTING REPLACE_EXISTING} </td>
* <td> If the target file exists, then the target file is replaced if it
* is not a non-empty directory. If the target file exists and is a
* symbolic link, then the symbolic link itself, not the target of
* the link, is replaced. </td>
* </tr>
* <tr>
* <td> {@link StandardCopyOption#ATOMIC_MOVE ATOMIC_MOVE} </td>
* <td> The move is performed as an atomic file system operation and all
* other options are ignored. If the target file exists then it is
* implementation specific if the existing file is replaced or this method
* fails by throwing an {@link IOException}. If the move cannot be
* performed as an atomic file system operation then {@link
* AtomicMoveNotSupportedException} is thrown. This can arise, for
* example, when the target location is on a different {@code FileStore}
* and would require that the file be copied, or target location is
* associated with a different provider to this object. </td>
* </table>
*
* <p> An implementation of this interface may support additional
* implementation specific options.
*
* <p> Moving a file will copy the {@link
* BasicFileAttributes#lastModifiedTime last-modified-time} to the target
* file if supported by both source and target file stores. Copying of file
* timestamps may result in precision loss. An implementation may also
* attempt to copy other file attributes but is not required to fail if the
* file attributes cannot be copied. When the move is performed as
* a non-atomic operation, and an {@code IOException} is thrown, then the
* state of the files is not defined. The original file and the target file
* may both exist, the target file may be incomplete or some of its file
* attributes may not been copied from the original file.
*
* <p> <b>Usage Examples:</b>
* Suppose we want to rename a file to "newname", keeping the file in the
* same directory:
* <pre>
* Path source = ...
* Files.move(source, source.resolveSibling("newname"));
* </pre>
* Alternatively, suppose we want to move a file to new directory, keeping
* the same file name, and replacing any existing file of that name in the
* directory:
* <pre>
* Path source = ...
* Path newdir = ...
* Files.move(source, newdir.resolve(source.getFileName()), REPLACE_EXISTING);
* </pre>
*
* @param source
* the path to the file to move
* @param target
* the path to the target file (may be associated with a different
* provider to the source path)
* @param options
* options specifying how the move should be done
*
* @return the path to the target file
*
* @throws UnsupportedOperationException
* if the array contains a copy option that is not supported
* @throws FileAlreadyExistsException
* if the target file exists but cannot be replaced because the
* {@code REPLACE_EXISTING} option is not specified <i>(optional
* specific exception)</i>
* @throws DirectoryNotEmptyException
* the {@code REPLACE_EXISTING} option is specified but the file
* cannot be replaced because it is a non-empty directory
* <i>(optional specific exception)</i>
* @throws AtomicMoveNotSupportedException
* if the options array contains the {@code ATOMIC_MOVE} option but
* the file cannot be moved as an atomic file system operation.
* @throws IOException
* if an I/O error occurs
* @throws SecurityException
* In the case of the default provider, and a security manager is
* installed, the {@link SecurityManager#checkWrite(String) checkWrite}
* method is invoked to check write access to both the source and
* target file.
*/
public static Path move(Path source, Path target, CopyOption... options)
throws IOException
其中参数中的CopyOption可选性有:
package java.nio.file;
/**
* Defines the standard copy options.
*
* @since 1.7
*/
public enum StandardCopyOption implements CopyOption {
/**
* Replace an existing file if it exists.
*/
REPLACE_EXISTING,
/**
* Copy attributes to the new file.
*/
COPY_ATTRIBUTES,
/**
* Move the file as an atomic file system operation.
*/
ATOMIC_MOVE;
}
我们看看kafka中怎么使用的,在kafka的org.apache.kafka.common.utils中有下面的代码:
/**
* Attempts to move source to target atomically and falls back to a non-atomic move if it fails.
*
* @throws IOException if both atomic and non-atomic moves fail
*/
public static void atomicMoveWithFallback(Path source, Path target) throws IOException {
try {
Files.move(source, target, StandardCopyOption.ATOMIC_MOVE);
} catch (IOException outer) {
try {
Files.move(source, target, StandardCopyOption.REPLACE_EXISTING);
log.debug("Non-atomic move of " + source + " to " + target + " succeeded after atomic move failed due to "
+ outer.getMessage());
} catch (IOException inner) {
inner.addSuppressed(outer);
throw inner;
}
}
}
参考资料
- Ensuring data reaches disk
- linux 同步IO: sync、fsync与fdatasync - CSDN博客
- sync(2) - Linux manual page
- fsync(2) - Linux manual page
- Everything You Always Wanted To Know About fsync() - xavier roche’s homework
- Linux OS: Write Barriers - 德哥@Digoal的日志 - 网易博客
- Linux Barrier I/O 实现分析与barrier内存屏蔽分析总结 - 综合编程类其他综合 - 红黑联盟
- Barriers and journaling filesystems [LWN.net]
- Linux/UNIX编程如何保证文件落盘
- storage - Really force file sync/flush in Java - Stack Overflow
- Java如何保证文件落盘?
版权申明
本站点所有内容,版权均归https://wenchao.ren所有,除非明确授权,否则禁止一切形式的转载协议
打赏


